Assessing Model Accuracy
Measuring the Quality of Fit
In regression setting, the most commonly-used measure is the mean square error(MSE), given by where is the prediction given by for th observation. The MSE will be small if the predict responses are very close to the true responses.
But we don't really care about the training MSE, but test MES. If we have a large number of test observations, we could compute where is previously unseen in training data.
However, if there is no test data, we can use cross-validation which is a method for estimating test MES using the training data.
There shows tree examples:
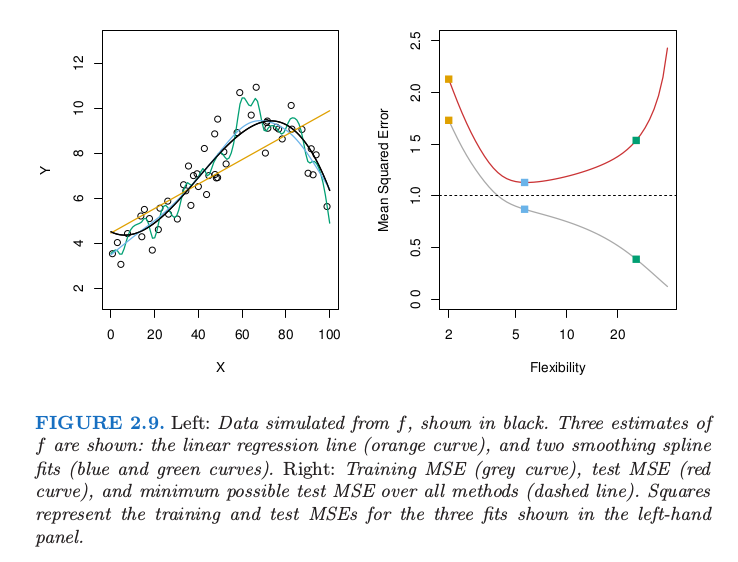
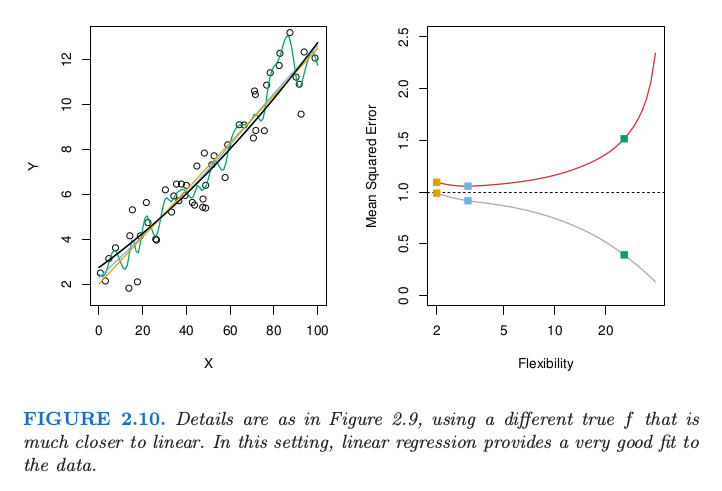
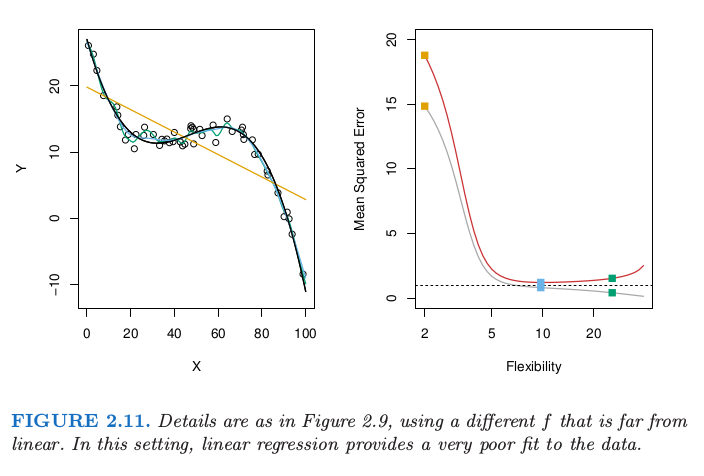
The Bias-Variance Trade-off
The MSE can be decomposed into tree parts. That is, This equation tells us in order to minimize the expected test MSE, we need to select a statistical learning method that simultaneously achieves low variance and low bias.
Variance refers to the amount by which would change if we estimate it using a different training dataset. Since the training data are used to fit the statistical learning method, different training data set will result in different . An ideal estimate for should not vary too much between different training data.
Bias refers to the error that introduced by approximating a real-life problem, which may be extremely complicated, by a much simpler model. For instance, linear regression assumes that there is a linear relationship between and . It is unlikely that any real-life problem has such a linear relationship, and this assumption will undoubtedly cause some bias in estimating . Generally, more flexible model result in less bias.
As a general rule, as we use more flexible methods, the variance will increase and bias will decrease.
Here gives a figure illustrate this equation for the examples showed in above section.
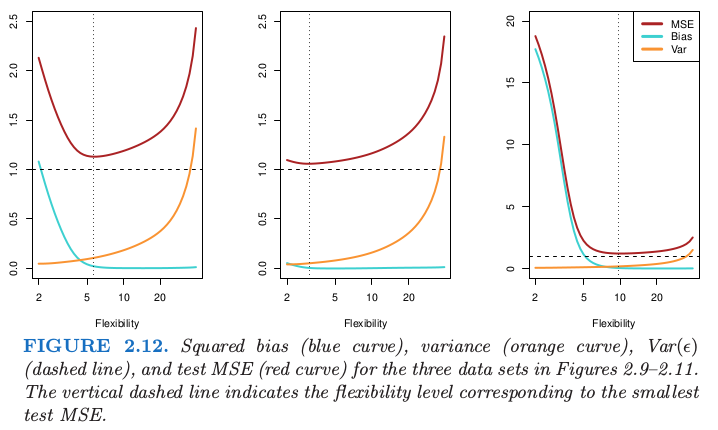
The Classification Setting
The most common approach for quantifying the accuracy of estimate is the training error rate. It is the proportion of mistakes that are made when we apply our estimate to the training observations: Here is the predicted class label for the th observation using . And is an indicator variable that equals 1 if and 0 if .
The test error rate associated with a set of test observations of form is given by A classifier is to assign each observation to the most likely class, given its predictor value. In other words, we can assign a test observation with predictor vector to the class for which is largest.
This is a conditional probability, and it is a very simple classifier called the Bayes classifier. The Bayes classifier produces the lowest possible test error rate, called the Bayes error rate. In general, the overall Bayes error rate is given by
But in reality, we don't know the data distribution, the conditional distribution of given , and that make computing the Bayes classifier impossible. Many approaches attempt to estimate the conditional distribution of given , and then classify a given observation to the class with highest estimate probability. One such method is the K-nearest neighbors (KNN) classifier. It estimate the conditional probability for the class as the fraction of points in whose response value equals to :
The figures below show the relationship between Bayes classifier and KNN classifier.
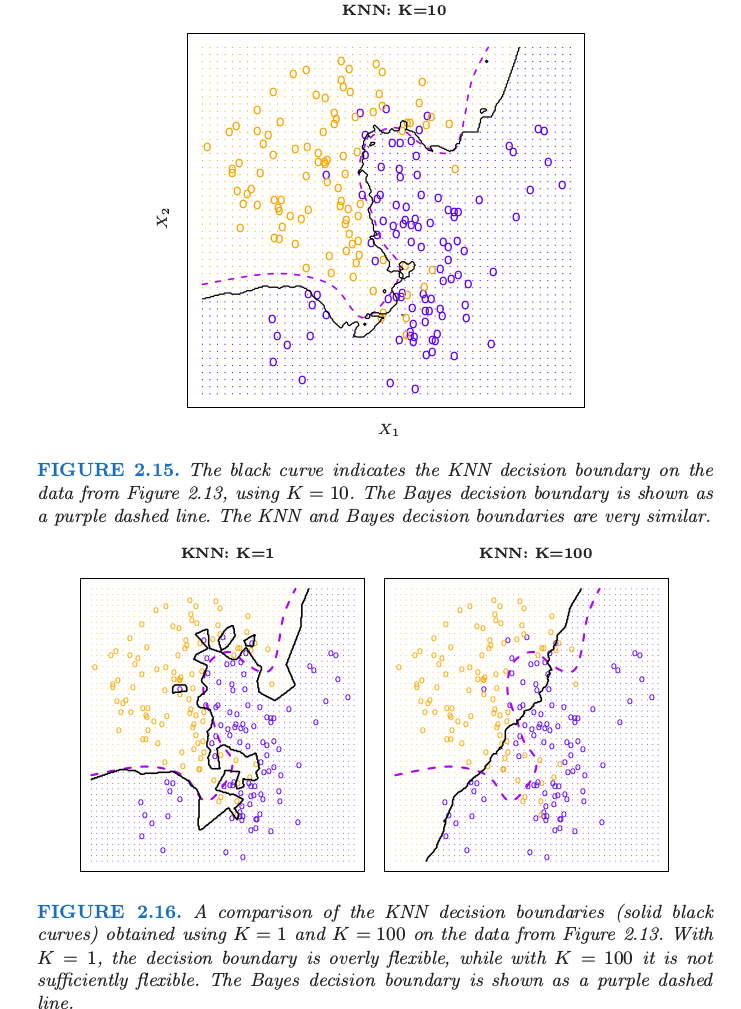
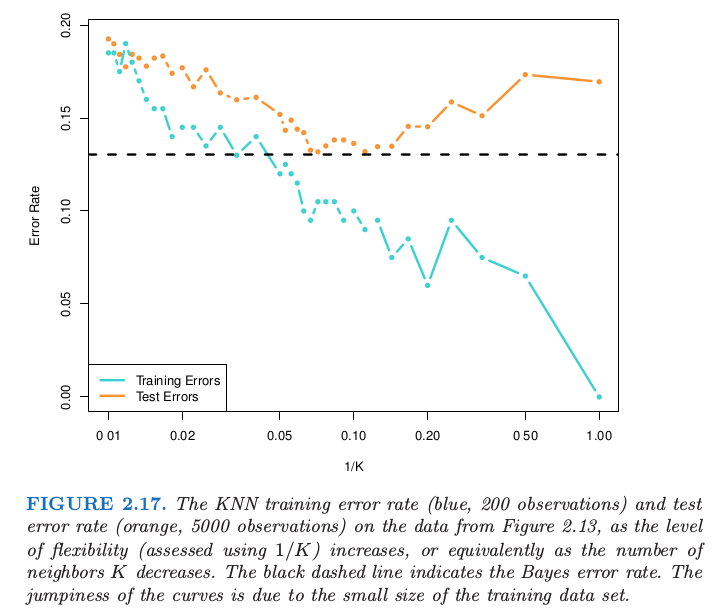
In both of regression and classification setting, choosing the correct level of flexibility is critical to the success of any statistical learning method. This will be discussed in later chapter.