Shrinkage Methods
By retaining a subset of the predictors and discarding the rest, subset selection produces a model that is interpretable and has possibly lower prediction error than the full model. However, because it is a discrete process—variables are either retained or discarded—it often exhibits high variance, and so doesn't reduce the prediction error of the full model. Shrinkage methods are more continuous, and don't suffer as much from high variability.
Ridge Regression
Ridge regression shrinks the regression coefficients by imposing a penalty on their size. The ridge coefficients minimize a penalized residual sum of squares,
Here is a complexity parameter that controls the amount of shrinkage: the larger the value of , the greater the amount of shrinkage. The coefficients are shrunk toward zero (and each other).
An equivalent way to write the ridge problem is which makes explicit the size constraint on the parameters.
The ridge solutions are not equivariant under scaling of the inputs, and so one normally standardizes the inputs before solving.
In addition, notice that the intercept has been left out of the penalty term. Penalization of the intercept would make the procedure depend on the origin chosen for ; that is, adding a constant to each of the targets would not simply result in a shift of the predictions by the same amount . We estimate by . The remaining coefficients get estimated by a ridge regression without intercept, using the centered .
We can get And In the case of orthonormal inputs, the ridge estimates are just a scaled version of the least squares estimates, that is, .
Ridge regression can also be derived as the mean or mode of a posterior distribution, with a suitably chosen prior distribution.
The singular value decomposition (SVD) of the centered input matrix gives us some additional insight into the nature of ridge regression. The SVD of matrix has the form And we can find that and , , , , .
Using the singular value decomposition we can write the least squares fitted vector as after some simplification. Well, in fact, . We should also notice that, the and are totally different orthogonal bases for the columns space of .
Now the ridge solution are where are the columns of . Like linear regression, ridge regression computes the coordinates of with respect to the orthonormal basis . It then shrinks these coordinates by the factors . This means that a greater amount of shrinkage is applied to the coordinates of basis vectors with smaller .
What does a small value of mean? The SVD of the centered matrix is another way of expressing the principal components of the variables in . The sample covariance matrix is given by , which is the eigen decomposition of (and of , up to a factor ). The eigenvectors (columns of ) are also called the principal components (or Karhunen–Loeve) directions of . The first principal component direction has the property that has the largest sample variance amongst all normalized linear combinations of the columns of . This sample variance is easily seen to be and in fact . The derived variable is called the first principal component of , and hence is the normalized first principal component.1
The definition of the effective degrees of freedom in ridge regression is given by
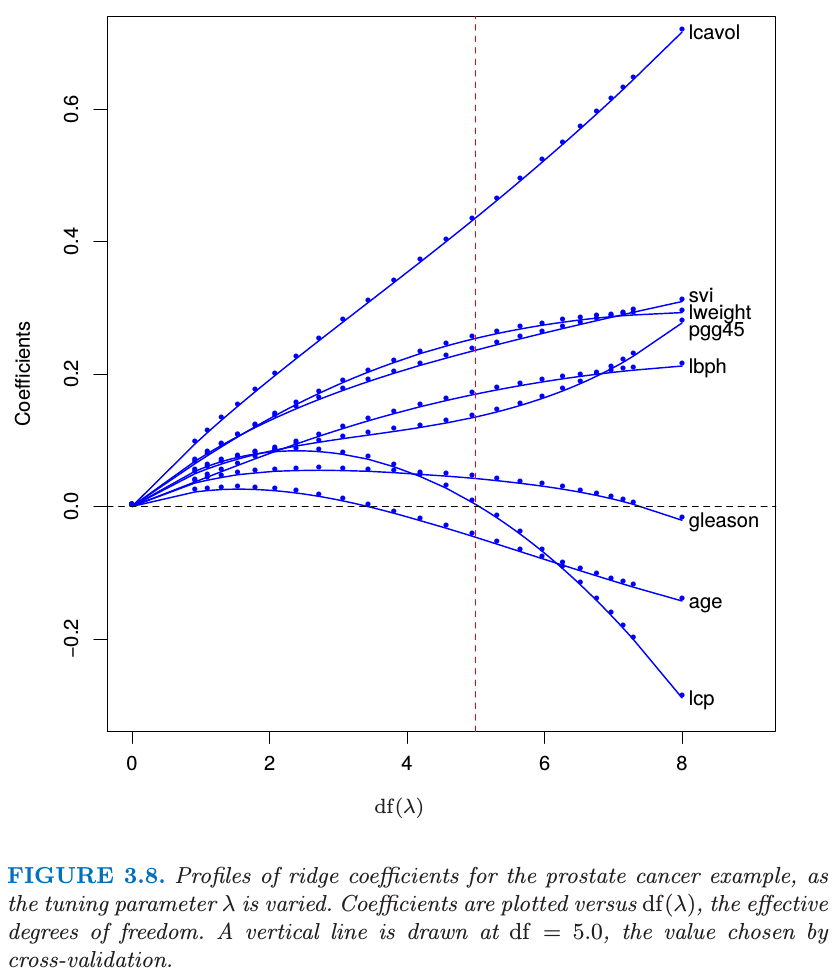
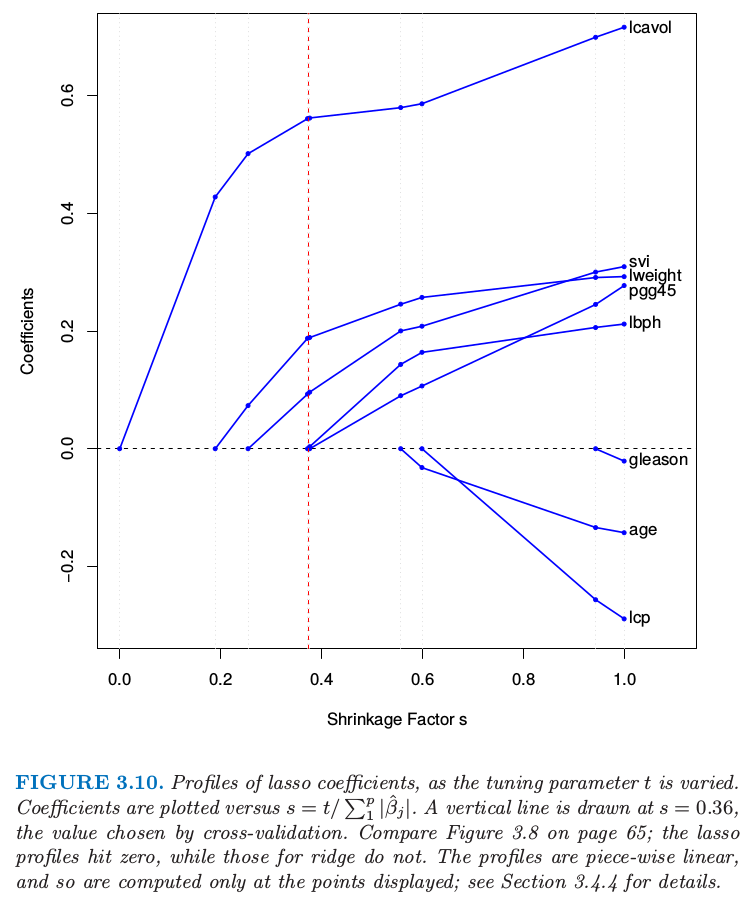
The Lasso
The lasso is a shrinkage method like ridge, with subtle but important differences. The lasso estimate is defined by Just as in ridge regression, we can re-parametrize the constant by standardizing the predictors; the solution for is , and thereafter we fit a model without an intercept.
We can also write the lasso problem in the equivalent Lagrangian form Notice the similarity of ridge regression. The ridge penalty is replaced by the lasso penalty . This latter constraint makes the solutions nonlinear in the , and there is no closed form expression as in ridge regression.If is chosen larger than (where , the least squares estimates), then the lasso estimates are the 's. On the other hand, for say, then the least squares coefficients are shrunk by about 50% on average. Like the subset size in variable subset selection, or the penalty parameter in ridge regression, should be adaptively chosen to minimize an estimate of expected prediction error.
Discussion: Subset Selection, Ridge Regression and the Lasso
In the case of an orthonormal input matrix X the three procedures have explicit solutions. Each method applies a simple transformation to the least squares estimate , as detailed in Table 3.4.

Ridge regression does a proportional shrinkage. Lasso translates each coefficient by a constant factor , truncating at zero. This is called "soft thresholding", and is used in the context of wavelet-based smoothing. Best-subset selection drops all variables with coefficients smaller than the th largest; this is a form of "hard-thresholding".
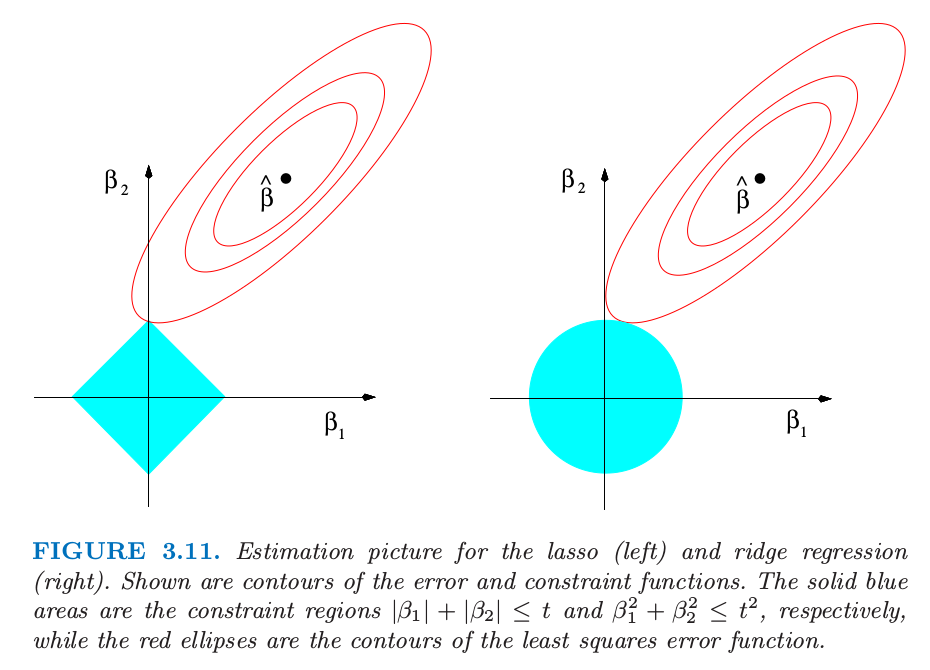
Back to the nonorthogonal case; some pictures help understand their relationship. Figure 3.11 depicts the lasso (left) and ridge regression (right) when there are only two parameters. The residual sum of squares has elliptical contours, centered at the full least squares estimate. The constraint region for ridge regression is the disk , while that for lasso is the diamond . Both methods find the first point where the elliptical contours hit the constraint region. Unlike the disk, the diamond has corners; if the solution occurs at a corner, then it has one parameter equal to zero. When , the diamond becomes a rhomboid, and has many corners, flat edges and faces; there are many more opportunities for the estimated parameters to be zero.
We can generalize ridge regression and the lasso, and view them as Bayes estimates. Consider the criterion for . The contours of constant value are shown in Figure 3.12, for the case of two inputs.
Thinking of as the log-prior density for , these are also the equi-contours of the prior distribution of the parameters. The value corresponds to variable subset selection, as the penalty simply counts the number of nonzero parameters; corresponds to the lasso, while to ridge regression. Notice that for , the prior is not uniform in direction, but concentrates more mass in the coordinate directions. The prior corresponding to the case is an independent double exponential (or Laplace) distribution for each input, with density and . The case (lasso) is the smallest such that the constraint region is convex; non-convex constraint regions make the optimization problem more difficult.
In this view, the lasso, ridge regression and best subset selection are Bayes estimates with different priors. Note, however, that they are derived as posterior modes, that is, maximizers of the posterior. It is more common to use the mean of the posterior as the Bayes estimate. Ridge regression is also the posterior mean, but the lasso and best subset selection are not.
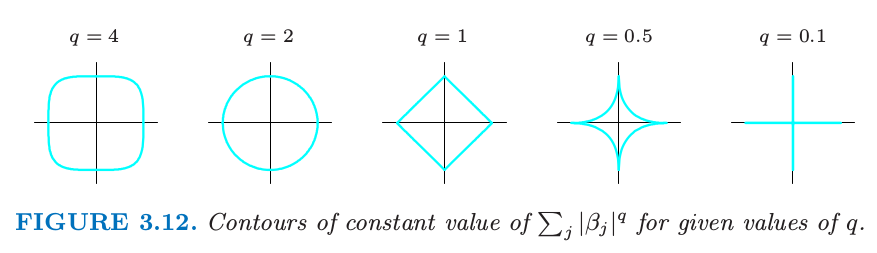
Looking again at the criterion (3.53), we might try using other values of besides 0, 1, or 2. Although one might consider estimating from the data, our experience is that it is not worth the effort for the extra variance incurred. Values of suggest a compromise between the lasso and ridge regression. Although this is the case, with , is differentiable at 0, and so does not share the ability of lasso for setting coefficients exactly to zero. Partly for this reason as well as for computational tractability, Zou and Hastie (2005) introduced the elastic-net penalty a different compromise between ridge and lasso. Figure 3.13 compares the penalty with and the elastic-net penalty with ; it is hard to detect the difference by eye. The elastic-net selects variables like the lasso, and shrinks together the coefficients of correlated predictors like ridge.

Least Angle Regression
LAR is intimately connected with the lasso, and in fact provides an extremely efficient algorithm for computing the entire lasso path as in Figure 3.10.
Forward stepwise regression builds a model sequentially, adding one variable at a time. At each step, it identifies the best variable to include in the active set, and then updates the least squares fit to include all the active variables.
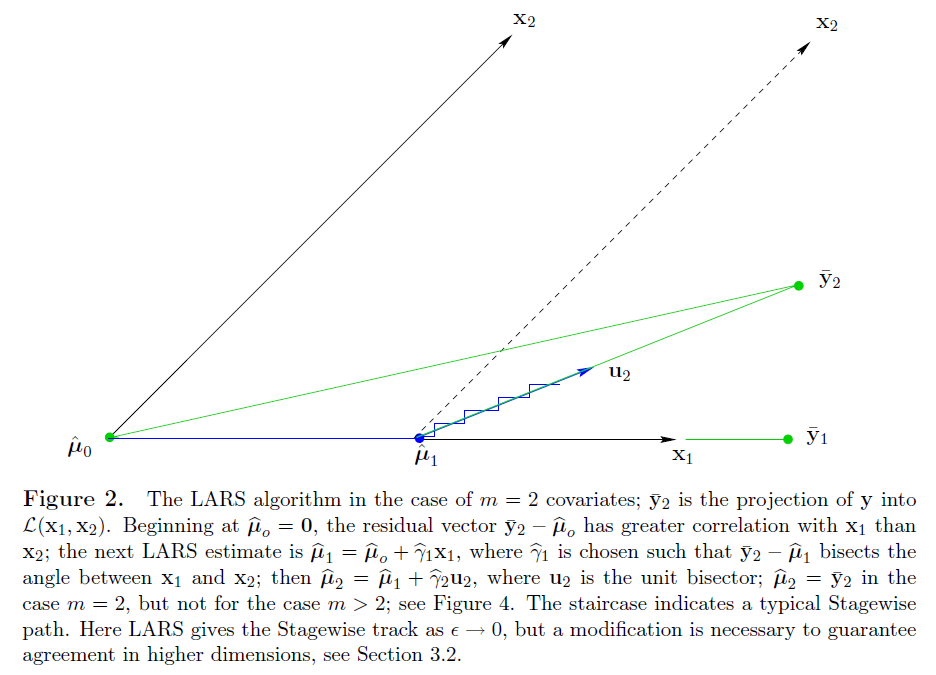
Least angle regression uses a similar strategy, but only enters "as much" of a predictor as it deserves. At the first step it identifies the variable most correlated with the response. Rather than fit this variable completely, LAR moves the coefficient of this variable continuously toward its least squares value (causing its correlation with the evolving residual to decrease in absolute value). As soon as another variable "catches up" in terms of correlation with the residual, the process is paused. The second variable then joins the active set, and their coefficients are moved together in a way that keeps their correlations tied and decreasing. This process is continued until all the variables are in the model, and ends at the full least-squares fit. Algorithm 3.2 provides the details. The termination condition in step 5 requires some explanation. If , the LAR algorithm reaches a zero residual solution after steps (the is because we have centered the data).

Suppose is the active set of variables at the beginning of the th step, and let be the coefficient vector for these variables at this step; there will be nonzero values, and the one just entered will be zero. If is the current residual, then the direction for this step is The coefficient profile then evolves as . If the fit vector at the beginning of this step is , then it evolves as , where is the new fit direction. The name "least angle" arises from a geometrical interpretation of this process; makes the smallest (and equal) angle with each of the predictors in is the new fit direction. Figure 3.14 shows the absolute correlations decreasing and joining ranks with each step of the LAR algorithm, using simulated data.
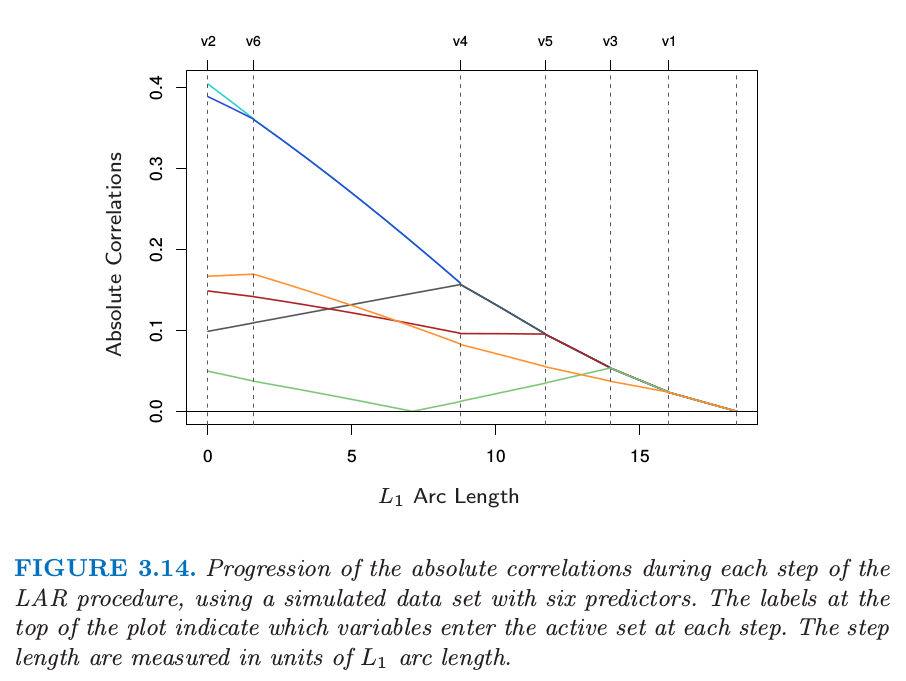
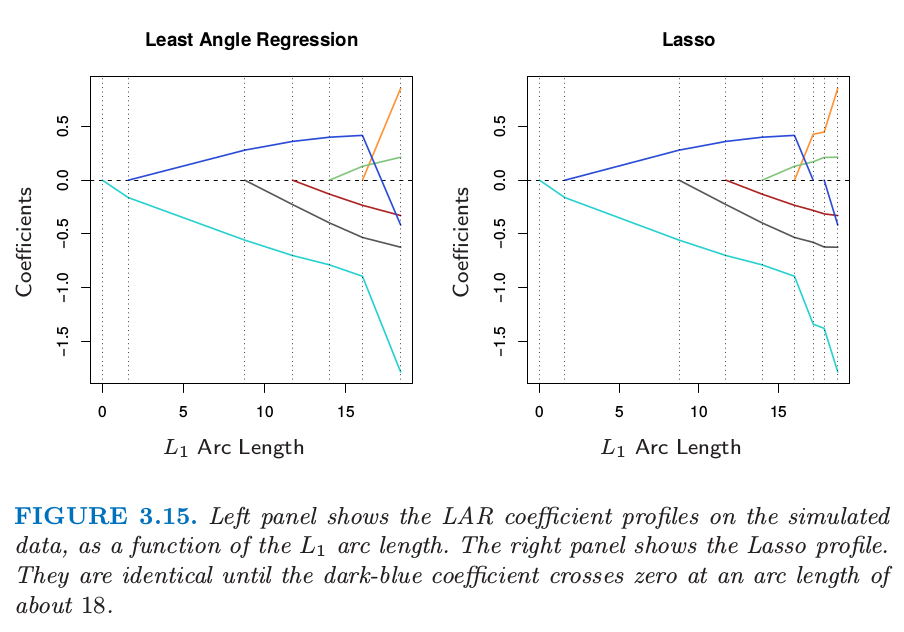
By construction the coefficients in LAR change in a piecewise linear fashion. Figure 3.15 [left panel] shows the LAR coefficient profile evolving as a function of their arc length 2 . Note that we do not need to take small steps and recheck the correlations in step 3; using knowledge of the covariance of the predictors and the piecewise linearity of the algorithm, we can work out the exact step length at the beginning of each step.
The right panel of Figure 3.15 shows the lasso coefficient profiles on the same data. They are almost identical to those in the left panel, and differ for the first time when the blue coefficient passes back through zero. For the prostate data, the LAR coefficient profile turns out to be identical to the lasso profile in Figure 3.10, which never crosses zero. These observations ead to a simple modification of the LAR algorithm that gives the entire lasso path, which is also piecewise-linear.
The algorithm can also been showed as below figure:
We now give a heuristic argument for why these procedures are so similar. Although the LAR algorithm is stated in terms of correlations, if the input features are standardized, it is equivalent and easier to work with inner-products. Suppose is the active set of variables at some stage in the algorithm, tied in their absolute inner-product with the current residuals . We can express this as where indicates the sign of the inner-product, and is the common value. Also . Now consider the lasso criterion, which we write in vector form
Let be the active set of variables in the solution for a given value of . For these variables is differentiable, and the stationarity conditions give Comparing (3.58) and (3.56), we see that they are identical only if the sign of matches the sign of the inner product. That is why the LAR algorithm and lasso start to differ when an active coefficient passes through zero; condition(3.58) is violated for that variable, and it is kicked out of the active set . The stationarity conditions for the non-active variables require that which again agrees with the LAR algorithm.
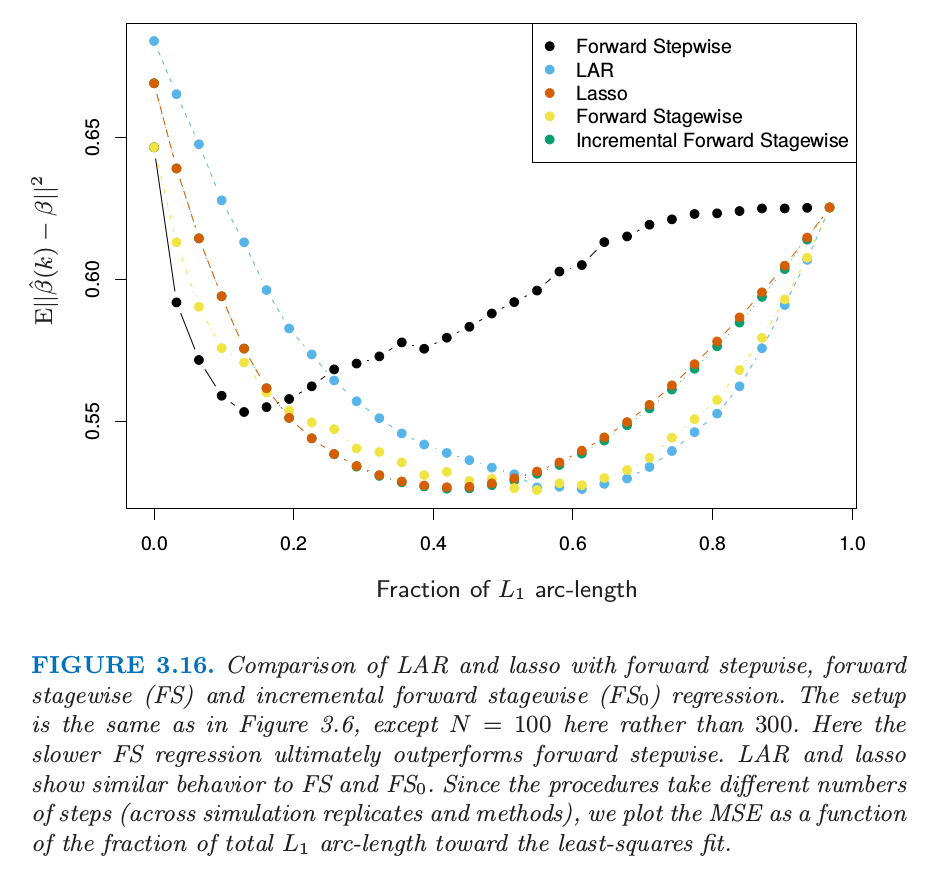
Figure 3.16 compares LAR and lasso to forward stepwise and stagewise regression.
Degrees-of-Freedom Formula for LAR and Lasso
Consider first a linear regression using a subset of features. If this subset is prespecified in advance without reference to the training data, then the degree of freedom used in the fitted model is defined to be . In classical statistics, the number of linearly independent parameters is what is meant by "degree of freedom".
We define the degree of freedom of the fitted vector as
Here refers to the sampling covariance between the predicted value and its corresponding outcome value . This makes intuitive sense: the harder that we fit to the data, the larger this covariance and hence .
Now for a linear regression with fixed predictors, it is easy to show that . Likewise for ridge regression, this definition leads to the closed-form expression: . In both these cases, is simple to evaluate because the fit is linear in .
1. Notice here. If we consider PCA as transforming a matrix into a different space, we can write it like and , for a diagonal matrix. PCA is finding the eigenvectors of as which is . And , just equals to . ↩
2. The arc-length of a differentiable curve for is given by , where . For the piecewise-linear LAR coefficient profile, this amounts to summing the norms of the changes in coefficients from step to step. ↩