What is Statistical Learning
In essence, statistical learning refers to a set of approaches to estimate . Let's look it in detail.
We can denote the input variables as . The inputs go by different names, like predictors, independent variables, features, or sometimes just variables. The output variable is often called as dependent variable or response, and it typically denoted as . We use these input variables to predict output variable, and we call this progress as statistical learning.
More generally, suppose we observed a quantitative response and different predictors, . We assume there is some relationship between and , which can be written in a very general form
Here is some fixed but unknown function of , and is a random error term, which should be independent of and has mean zero.
Why Estimate
In many situations, we already have a set of inputs , but the output cannot be easily obtained. In this setting, since the error term average zero, we can predict using where represents our estimate for , and represents the prediction for .
In general, isn't a perfect estimation of . Then, how to measure the accuracy of our prediction?
The accuracy of as a prediction of depends on two quantities, which we called reducible error and irreducible error. We can improve the accuracy of to reduce the reducible error. However, even if there exists an by using appropriate statistical technologies can perfectly estimate , our prediction will still have error in it! Because is also a function of . This error is irreducible.
Consider a given estimate and a set of predictions , which yields the prediction . Then it is easy to show that What we focus most is on the techniques for estimating with the aim of minimizing the reducible error. And irreducible error will always provide an upper bound on the accuracy of our prediction for . And this bound is almost always unknown in practice.
If we are interested in the way how is effected with change, we cannot treat as a black box, we need to know the exact form of .
How to estimate
Our goal is to apply statistical learning methods to the training data in order to estimate the unknown function . Most statistical learning methods can be charactered as parametric or non-parametric.
Parametric methods
Parametric methods involve a two-step model-based approach.
- First, we make an assumption about the functional form, or shape of .
- After a model has been selected, we need a procedure that uses the training data to fit or train the model.
Non-parametric methods
Non-parametric methods do not make explicit assumption of function form of . Instead they seek an estimate of that gets as close to the data points as possible without being to rough or wiggly.
Since non-parametric methods avoid the assumption of a particular functional form of , they have the potential to accurately fit a wider range of possible shapes for . However, the major disadvantage is it requires a very large number of observations in order to obtain an accurate estimate of
The Trade-off Between Prediction Accuracy and Model Interpretability.
The relationship between flexibility and interpretability is showed as below:
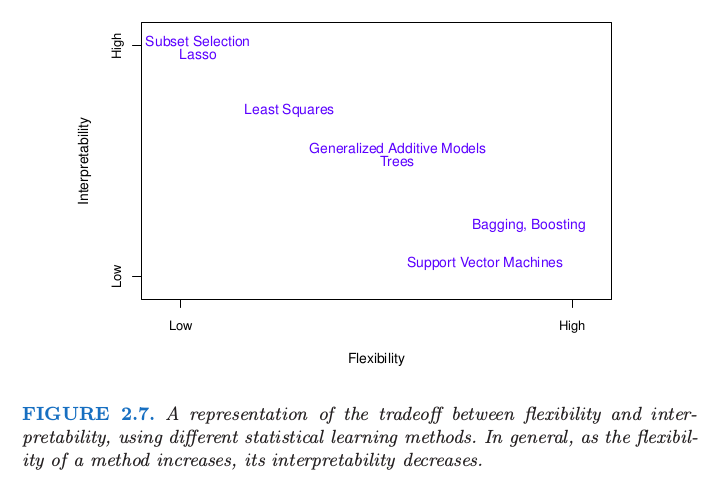
However, we will often obtain more accurate predictions using a less flexible model. It may seem counterintuitive at first glance, but highly flexible model may cause over-fitting.
Supervised versus Unsupervised
Most statistical learning falls into to categories: supervised and unsupervised.
Supervised learning has a response variable , but unsupervised learning has no response variable to supervise our analysis. Cluster analysis is a typical unsupervised learning method.
If the predictor can be measured cheaply but the corresponding response are much more expensive to collect, we refer this setting as a semi-supervised learning problem.
Regression versus Classification
Variables can be characterized as either quantitative or qualitative (also called categorical).
We tend to refer to problems with a quantitative response as regression problems, while those involving a qualitative response are referred to classification.