In many situations we have a large number of inputs, often very correlated. The methods in this section produce a small number of linear combinations of the original inputs , and the are then used in place of as inputs in the regression.
Principal Components Regression
Principal component regression forms the derived input columns , and then regresses on for some . Since the are orthogonal, this regression is just a sum of univariate regressions: where . So then we can find out that
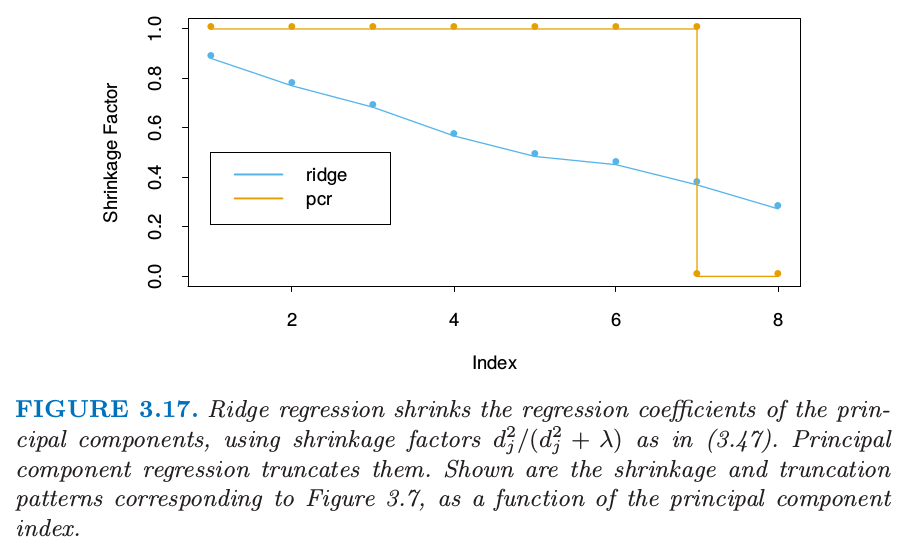
As with ridge regression, principle components depends on the scaling of the inputs, so typically we first standardize them. Note that if we would just get back the usual least squares estimates, since the columns of span the column space of . For we get a reduced regression. We see that principle regression is very similar to ridge regression: both operate via the principal components of the input matrix. Ridge regression shrinks the coefficients of the principal components, shrinking more depending on the size of the corresponding eigenvalue; principal components regression discard the smallest eigenvalue components. Figure 3.17 illustrates this.
Partial Least Squares
This technique also constructs a set of linear combination of the input for regression, but unlike principal components regression it uses (in addition to ) for this construction. PLS begins by computing for each . From this we construct the derived input , which is the first partial least squares direction. The procedure is described fully in algorithm 3.3

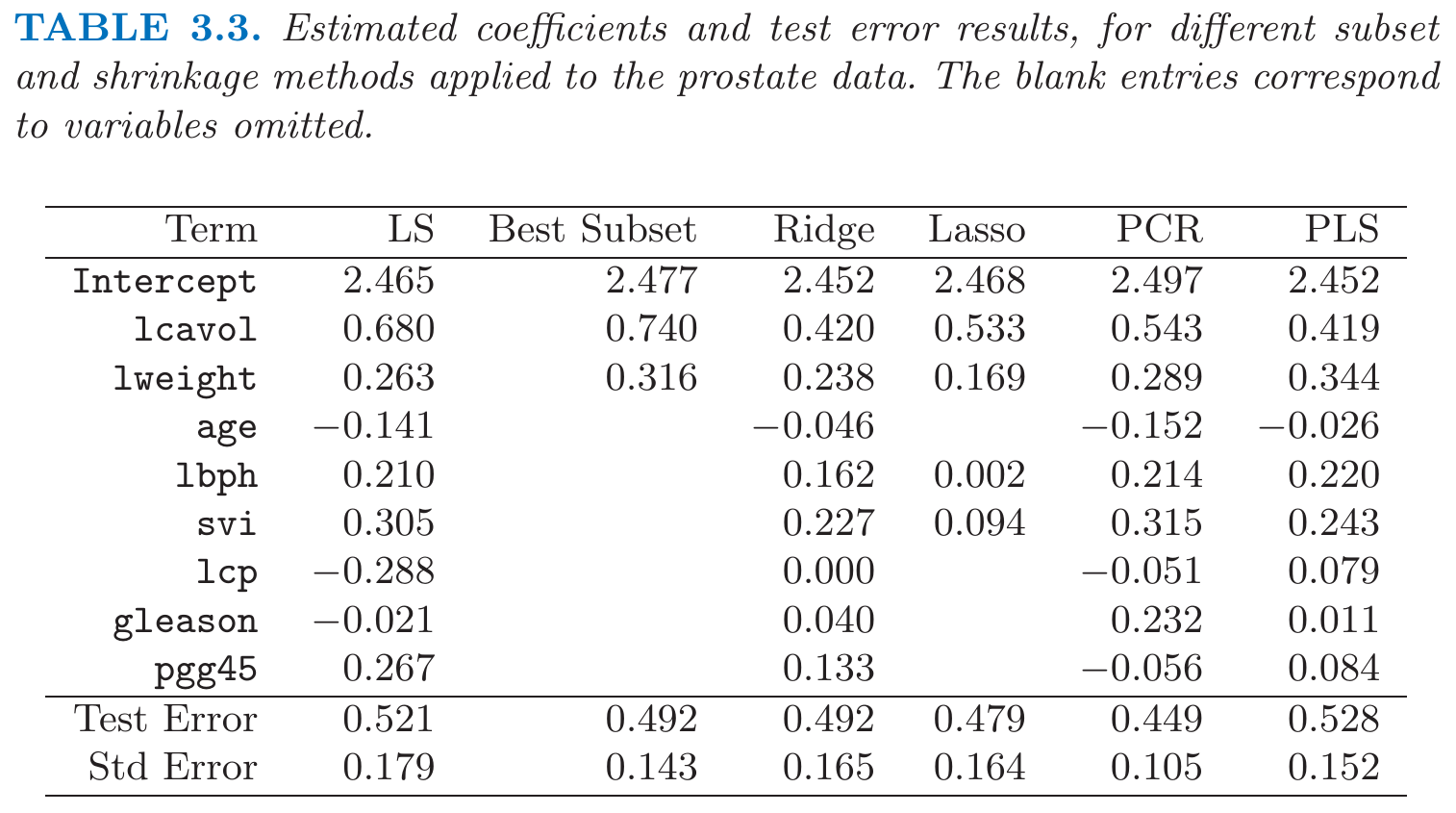
In the prostate cancer example, cross-validation chose PLS directions in Figure 3.7. This produced the model given in the rightmost column of Table 3.3.
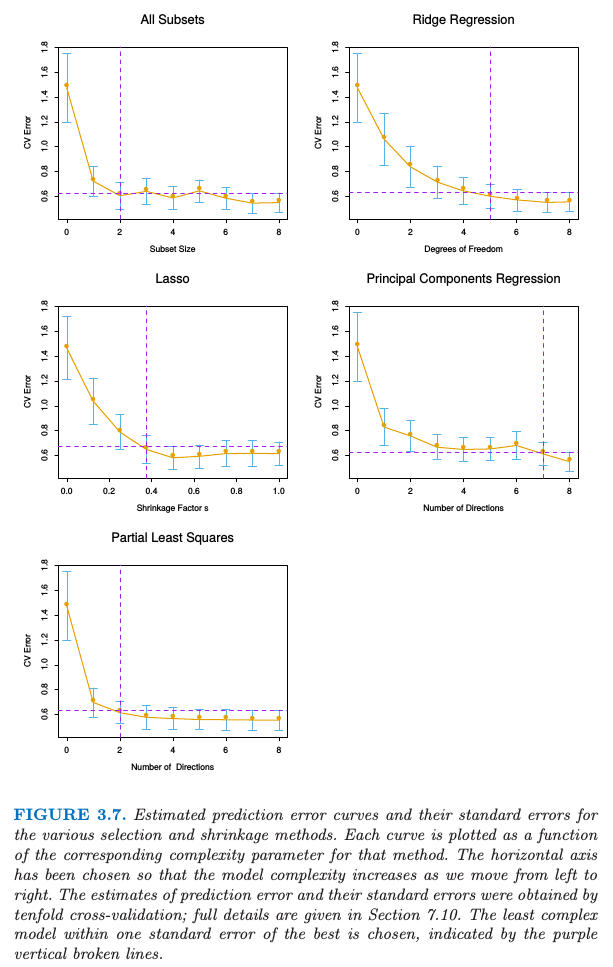
Partial least squares uses the response to construct its directions, its solution path is a nonlinear function of . It can be shown that partial least squares seeks directions that have high variance and have high correlations with the response, in contrast to principal components regression which keys only on high variance. In particular, the th principal component direction solves: where is the sample covariance matrix of the . The condition ensures that is uncorelated with all the previous linear combinations . The th PLS direction solves: