Linear Regression Models and Least Squares
As introduced in Chapter 3, we have input vector , and want to predict a real-valued output . The linear regression has the form as The linear model assumes that the regression function is linear, or that the linear model is reasonable approximation. Here the 's are unknown parameters or coefficients, and the variables can come from different sources:
- quantitative inputs;
- transformations of quantitative inputs, such as log, square-root, or square;
- basis expansions, such as , leading to a polynomial representation;
- numeric or dummy coding of the level of qualitative inputs.
- interaction between variables, such as .
No mater the source of the , the model is linear in the parameters.
Typically we have a set of training data from which to estimate the parameters . The most popular estimation method is least squares, in which we pick the coefficients to minimize the residual sum of squares From a statistical point of view, this criterion is reasonable if the training observations represent independent random draws from their population. Even if 's were not drawn randomly, the criterion is still valid if the 's are conditionally independent given the input .
We can rewrite as Differentiating with respect to we obtain Assuming that has full columns rank, and hence is positive definite, we set the first derivative to zero to obtain the unique solution The fitted values at training inputs are The matrix is called the "hat" matrix.
We can consider the least squares estimate in a different way showed as below:
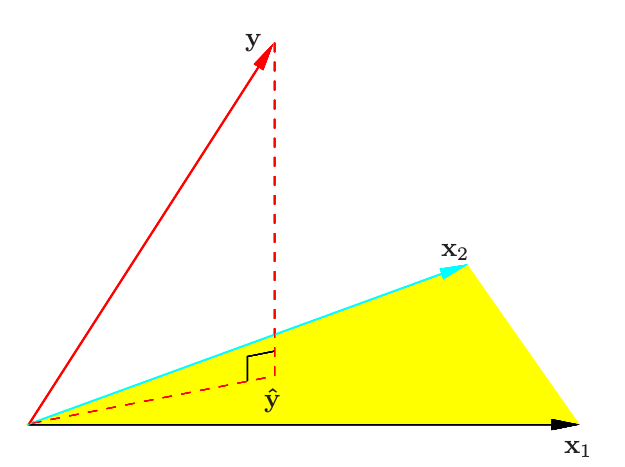 We denote the column vectors of by , with . We denote . And we can find , since . We minimize by choosing so that is orthogonal to this subspace. The matrix is also called projection matrix.
We denote the column vectors of by , with . We denote . And we can find , since . We minimize by choosing so that is orthogonal to this subspace. The matrix is also called projection matrix.
It might happen that the columns of are not linearly independent, so that is not of full rank. In this situation, the features are typically reduced by filtering or else the fitting is controlled by regularization (Section 5.2.3 and Chapter 18)
Up to now we have made minimal assumptions about the true distribution of the data. In order to pin down the sampling properties of , we now assume the observations are uncorrelated and have constant variance , and that are fixed. The variance-covariance matrix of the least square parameter estimates is Typically one estimates the variance by The rather than makes an unbiased estimate of : .
Usually, we need to test for the significance of groups of coefficients simultaneously. For example, to test if a categorical variable with levels can be excluded from a model, we need to test whether the coefficients of the dummy variables used to represent the levels can all be set to zero. Here we use the statistic, where is the residual sum-of-squares for the least squares fit of the bigger model with parameters, and the same for the nested smaller model with parameters, having parameters constrained to be zero.
The Gauss-Markov Theorem
One of the most famous results in statistics asserts that the least squares estimates of the parameters have the smallest variance among all linear unbiased estimates. We focus on estimates of any linear combination of the parameters ; for example, predictions are of this form. The least squares estimate of is
Considering X to be fixed, this is a linear function of the response vector . If we assume the linear model is correct, is unbiased since The Gauss-Markov theorem states that if we have any other linear estimator that is unbiased for , that is, , then Consider the mean squared error of an estimator in estimating : The first term is the variance, while the second term is the squared bias. The Gauss-Markov theorem implies that the least squares estimator has the smallest mean squared error of all linear estimators with no bias.
Multiple Regression from Simple Univariate Regression
The linear model with inputs is called the multiple linear regression model. The least squares estimates for this model are best understood in terms of the estimates for the univariate linear model, as we indicate in this section.
Suppose first that we have a univariate model with no intercept, that is, The least squares estimate and residuals are In convenient vector notation, we let are define the inner product between and . Then we can write Suppose that the inputs are orthogonal; that is for all . It is easy to check that the multiple least squares estimates are equal to . In other words, when the inputs are orthogonal, they have no effect on each other's parameter estimates in the model.
Suppose that we have an intercept and single input . Then the least squares coefficient of has the form where , and , the vector of ones. We can view the estimate as the result of two applications of the simple regression. The steps are:
- regress on to produce the residual ;
- regress on the residual to give the coefficient .
In this procedure, "regress on " means a simple univariate regression of on with no intercept, producing coefficient and residual vector . We say that is adjusted for , or is "orthogonalized" with respect to .
This procedure can be shown as below:

The algorithm is
- Initialize .
- For Regress on to produce coefficients and residual vector .
- Regress on the residual to give the estimate .
The result of this algorithm is And we can get which means the precision of depends on the length of the residual vector ; this represents how much of is unexplained by other 's.
We can represent the algorithm step2 in matrix form where has as columns the , and is the upper triangular matrix with entries . Introducing the diagonal matrix with th diagonal entry , we get the so-called QR decomposition of . Here is an orthogonal matrix, , and is a upper triangular matrix.
The decomposition represents a convenient orthogonal basis for the column space of . It is easy to see, for example, that the least squares solution is given by
Multiple Outputs
Suppose we have multiple outputs that we wish to predict from our inputs . We assume a linear model for each output With training cases we can write the model in matrix notation Here is the matrix, with entry , is the input matrix, is the matrix of parameters and is the matrix of errors. A straightforward generalization of the univariate loss function is The least squares estimates have exactly the same form as before If the errors are correlated, then it might seem appropriate to modify into suppose . Here is the vector function , and the vector of responses for observation .